Problem
I wanted to convert two FC ports to CNA (10Gb eth) mode on a Netapp AFF-300. The ports in question are 0e and 0f.

Steps
The following will work for FAS units as well.
Display internfaces:
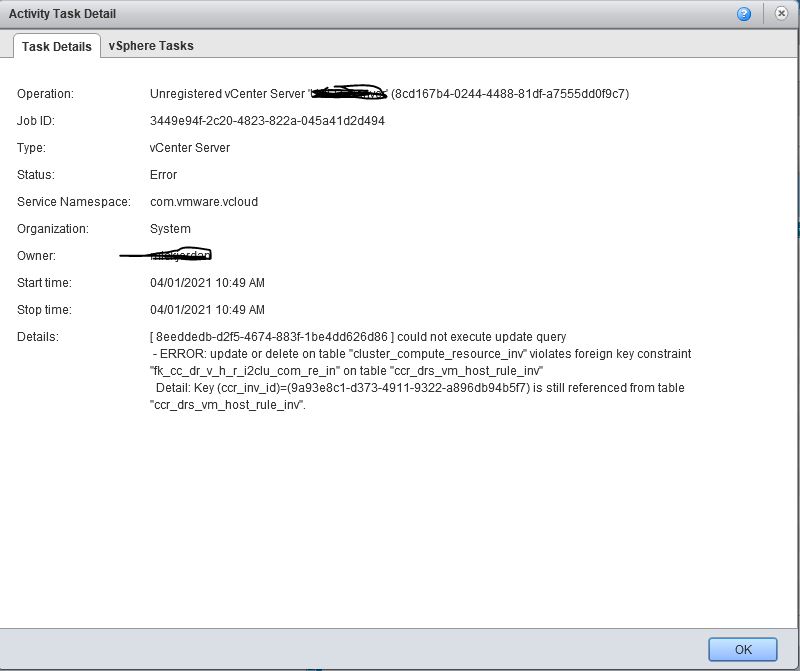
sannapp02::> ucadmin show
Current Current Pending Pending Admin
Node Adapter Mode Type Mode Type Status
———— ——- ——- ——— ——- ——— ———–
sannapp02-01
0e fc target – – online
sannapp02-01
0f fc target – – online
annapp02-01
0g fc target – – online
sannapp02-01
0h fc target – – online
sannapp02-02
0e fc target – – online
sannapp02-02
0f fc target – – online
psannapp02-02
0g fc target – – online
psannapp02-02
0h fc target – – online
8 entries were displayed.
2) Disable relevant Interfaces on Node 2
network fcp adapter modify -node sannapp02-02 -adapter 0e -status-admin down network fcp adapter modify -node sannapp02-02 -adapter 0f -status-admin down
3) Change Mode
system node hardware unified-connect modify -node sannapp02-02 -adapter 0e -mode cna
You will get the following option:
Warning: Mode on adapter 0e and also adapter 0f will be changed to cna.
Do you want to continue? {y|n}: y
Any changes will take effect after rebooting the system. Use the "system node reboot" command to reboot.
3) Reboot Node 2
system node reboot -node sannapp02-02
4) Enable interfaces on Node 2
network fcp adapter modify -node sannapp02-02 -adapter 0e -status-admin up network fcp adapter modify -node sannapp02-02 -adapter 0f -status-admin up
Repeat the steps above with Node 1