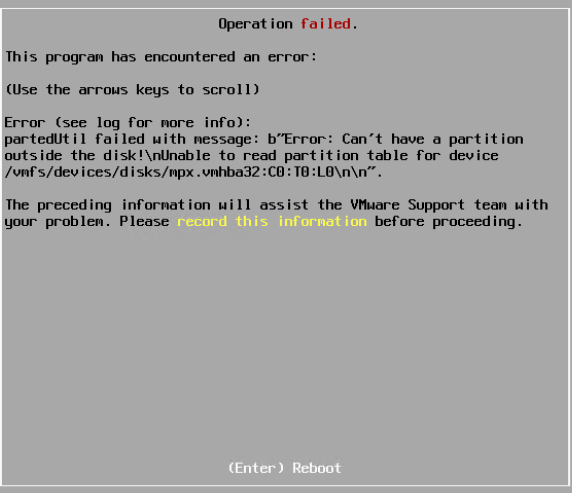
In this guide I will be setting up a Rocky Linux 8 machine a Veeam Repository – which connects to back end storage (10.9.9.241).
The guide assumes the backup storage and ACLs etc have all been set up.
Install initiator Utilities
dnf -y install iscsi-initiator-utils
Install Mulipathd
dnf -y install device-mapper-multipath
Copy the multipath config
cp /usr/share/doc/device-mapper-multipath/multipath.conf /etc/multipath.conf
Enable multipathd
systemctl --now enable device-mapper-multipath
Set up the multipathing in the initramfs system
dracut --force --add multipath
Edit the iscsi initiator name:
vi /etc/iscsi/initiatorname.iscsi
Change name to eg myhost-01
InitiatorName=iqn.1994-05.com.redhat:myhost-01
Add ISCSI Target
iscsiadm -m discovery -t sendtargets -p 10.9.9.241
Note: If you ever delete an ISCSI Target:
iscsiadm -m discovery -t sendtargets -p 10.9.9.241 -o delete
Log the iscsi into target
iscsiadm -m node --login
Show sessions
iscsiadm -m session -o show
Check mulitpathing
multipath -ll
Output:
mpatha (36d039ea000296cfd000000d8617251f8) dm-3 NETAPP,INF-01-00
size=100T features=’3 queue_if_no_path pg_init_retries 50′ hwhandler=’1 alua’ wp=rw
-+- policy='service-time 0' prio=10 status=active
|- 22:0:0:0 sde 8:64 active ready running
|- 20:0:0:0 sdc 8:32 active ready running
|- 21:0:0:0 sdd 8:48 active ready running
– 23:0:0:0 sdf 8:80 active ready running
Take note of WWID. In this case 36d039ea000296cfd000000d8617251f8)
Edit multipathing config
vi /etc/multipath.conf
Uncomment/Edit – following lines
multipaths {
multipath {
path_grouping_policy multibus
path_selector "round-robin 0"
failback manual
rr_weight priorities
no_path_retry 5
}
multipath {
wwid 36d039ea000296cfd000000d8617251f8
alias VEEAM-REP01
}
}
Restart Multipathd
systemctl restart multipathd
List mulitpaths again
multipath -ll
Output – Note the new name – VEEAM-REP01
mpatha (VEEAM-REP01) dm-3 NETAPP,INF-01-00
size=100T features=’3 queue_if_no_path pg_init_retries 50′ hwhandler=’1 alua’ wp=rw
-+- policy='service-time 0' prio=10 status=active
|- 22:0:0:0 sde 8:64 active ready running
|- 20:0:0:0 sdc 8:32 active ready running
|- 21:0:0:0 sdd 8:48 active ready running
– 23:0:0:0 sdf 8:80 active ready running